学着制作爬虫,听说 Python 界里的 Scrapy 是个神器,就尝试着写点试试,学习一下。
首先是安装 Scrapy
我使用的环境是 MacOSX,遇到了一些坑,之后说
建议: 使用 homebrew 并使用 brew 上的 python 进行开发学习
- 安装 homebrew (网上的资料大把,我就不再赘述了)
- 安装 python 2.7.11 本人用的是这个版本。看你的喜好吧。
brew install python - 使用 easy_install 安装 pip
easy_install pip - 然后使用 pip 安装 scrapy 这个步骤中,如果网络访问国外资源不是很好,可以使用国内的源,比如使用
豆瓣源
pip install scrapy - (坑) 通常情况下,scrapy 依赖的
PIL不会自动安装,需要手工安装。但在 MacOSX 下安装时会遇问题。
pip install PIL
Collecting PIL
Could not find a version that satisfies the requirement PIL (from versions: )
No matching distribution found for PIL
填坑 ( 解决办法 )
我参考了这篇资料 Mac 安装 PIL。
跟着我来一起做 :P
- 安装依赖
brew install freetype
ln -s /usr/local/Cellar/freetype/2.6_1/include/freetype2 /usr/local/include/freetype
pip install Pillow --trusted-host mirrors.aliyun.com
注意: 上面的是,用 Pillow 替代了 PIL
- 验证 : 直接 python 进入交互状态
执行
from PIL import Image
如果没有报错,就说明 PIL 模块可以正常执行了。
整体架构
引用一张 官方 的图来说明吧
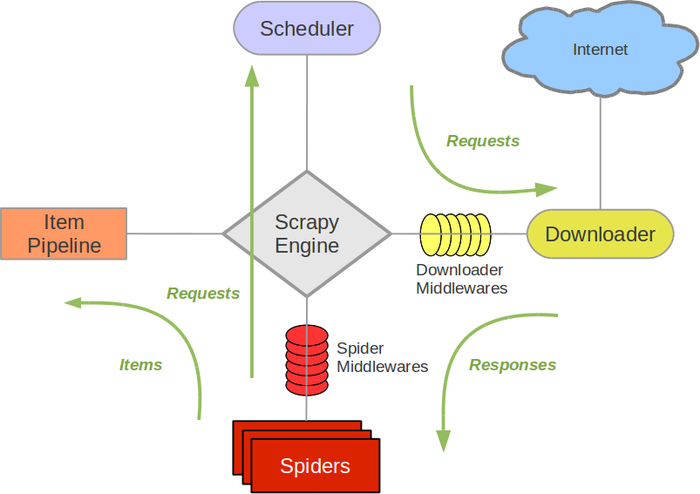
引擎 (Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
调度器 (Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
下载器 (Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
蜘蛛 (Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析 response 并提取 > item(即获取到的 item) 或额外跟进的 URL 的类。 每个 spider 负责处理一个特定 (或一些) 网站。
项目管道 (Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件 (Downloader Middlewares),位于 Scrapy 引擎和下载器之间的钩子框架,主要是处理 Scrapy 引擎与下载器之间的请求及响应。
蜘蛛中间件 (Spider Middlewares),介于 Scrapy 引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件 (Scheduler Middlewares),介于 Scrapy 引擎和调度之间的中间件,从 Scrapy 引擎发送到调度的请求和响应。
照着网上的例子先写点东西试试
(代码整理之后,会放到 Github 上)
待开发的爬虫
- 爬
豆瓣图书列表 - 爬
猎骋职位信息 - 爬
开源中国的博文、技术文档 - 爬
图片大全的图集
先这些吧
疑问
不知道 Scrapy 是否会对已经抓取的页面内容进行临时缓存
在网上没查到,scrapy 的源码还没来得及看,待观察。
[x] 2016-07-28
可以使用 Enable and configure HTTP caching 配置,来设置本地文件层的缓存。就在
settings.py文件的最后边,默认是禁用状态。参考手册设置一下即可。
我的理解
- Scrapy 的
startproject创建的项目,概念上不要过于执着于就是针对一个数据源的网站进行抓取,而是要当成你自己的爬虫项目,即可能数据源来自不同的网站。
-- 待续 --

